

The twin disciplines of data management and analytics have dominated the minds and wallets of executives for over three decades, helping to drive informed decisions, optimize processes and improve business performance.
Effective data management is the foundation for business teams to better understand their customers, identify areas for improvement and make data-driven decisions with analytics.
Having the ability to manage and analyze data effectively can provide a significant competitive advantage, although many organizations find themselves at a disadvantage when their legacy investments and technology debt mean that they can’t keep pace with the exploding growth in both data and the business questions arising from that data.
The rise and fall of the traditional data warehouse
For at least two decades, the data warehouse had been a popular architecture solution for managing an organization’s structured data, storing both current and historical data in a single location, and used as the common source for creating analytical reports and dashboards.
However, as the volumes, varieties and velocities of data have evolved since the earliest days of the dot-com boom, traditional data warehouses have struggled to adapt and survive in their classical incarnations, and are often considered no-longer sufficient to meet the needs of modern organizations with complex, fast-moving and hybrid environments.
Firstly, these last-generation data warehouses have issues around scalability, where the inability to process large volumes of data quickly can become a bottleneck for organizations looking to ingest and process data from operational systems, cloud-sources or Internet of Things (IoT) data.
Secondly, enterprise data warehouses were notoriously expensive – both to set up and maintain, making them less attractive to organizations with smaller budgets. Larger companies, on the other hand, had to deal with complexities involving appliances, large implementation teams and inflexible vendors with a myriad of add-on modules and customizations. For the enterprise, it was frequently the case that a data warehouse comprised both a large up-front capital expenditure and heavy, ongoing operational costs for maintenance and administration.
But most of all, it came down to flexibility. Traditional data warehouses struggled with the emerging variety of data types and analytical workflows that were now being demanded from data scientists, machine learning engineers and self-service business users.
The perfect storm in data management
As dissatisfaction grew with the traditional data warehousing approach, it was only natural that disruption would arrive, but did anyone expect it to take the form of a small, cuddly yellow elephant?

Hadoop – a distributed computing ecosystem – arrived on the scene in 2006 and immediately found its capabilities well-suited to the perfect storm of change at the heart of data management.
Whether it was handling data with changing or lightly-specified formats (known variously as unstructured or semi-structured data), the ability to leverage the emerging cloud computing scene or to take advantage of the dramatic drop in cost of both data storage and compute, Hadoop was on the lips of every data practitioner and executive looking for ways to handle the ‘big data’ gold rush.
The data lake had arrived.
As the ‘Hadoopiverse’ (with apologies to Marvel) evolved, new capabilities arose and matured, mimicking many of the last-generation functions of the data warehouse-era stack, but inside the data lake instead. HDFS for file management, MapReduce for data processing (later replaced with Spark for in-memory processing – more of which later), Pig and Hive for SQL-like query and analysis, Mahout for distributed machine learning, and many, many more members of the Hadoop ‘zoo’.
However, the very flexibility that made the platform popular for data acquisition and processing ultimately ended up as its Achilles heel. Data lakes suffered from data being dumped into the platform without suitable oversight or documentation, leading to serious challenges for data and governance teams who needed to keep track of exactly what was going on. Instead of the high-quality, highly-curated structured data from a data warehouse, the data lake became the wild west, with data quality, consistency and reliability issues galore.
The data lake metaphor devolved into the data swamp: an uncontrolled data sprawl with limited governance and a huge potential risk for security and privacy.
Let’s meet in the middle: The emergence of the data lakehouse
Traditional approaches like data warehouses are not able to keep up with the sheer volume and variety of data, leading to silos, high costs, and complexity, and with data lakes overpromising and under delivering as the heir apparent, a hybrid approach has gained popularity in recent years: the data lakehouse.
In contrast to earlier approaches, the data lakehouse aims to provide a unified platform for managing structured, semi-structured, and unstructured data, as well as supporting a variety of data workloads, including data warehousing, business intelligence, AI/ML, and streaming.
Gartner calls this a ‘converged’ data architecture that combines and unifies the architectures and capabilities of both a data warehouse and a data lake, deployed on a single (usually, cloud-based) platform.
With this approach, a lakehouse architecture delivers a simpler, cleaner design with fewer intermediate steps between data sources and refined data ready for analytics, data science or downstream delivery.
VC firms like Andreessen-Horowitz have noted the rise of the data lakehouse at the heart of their investment strategy for so-called ‘multimodal’ data processing (that is, processing of data above and beyond simple structured data alone).
(https://a16z.com/2020/10/15/emerging-architectures-for-modern-data-infrastructure/)
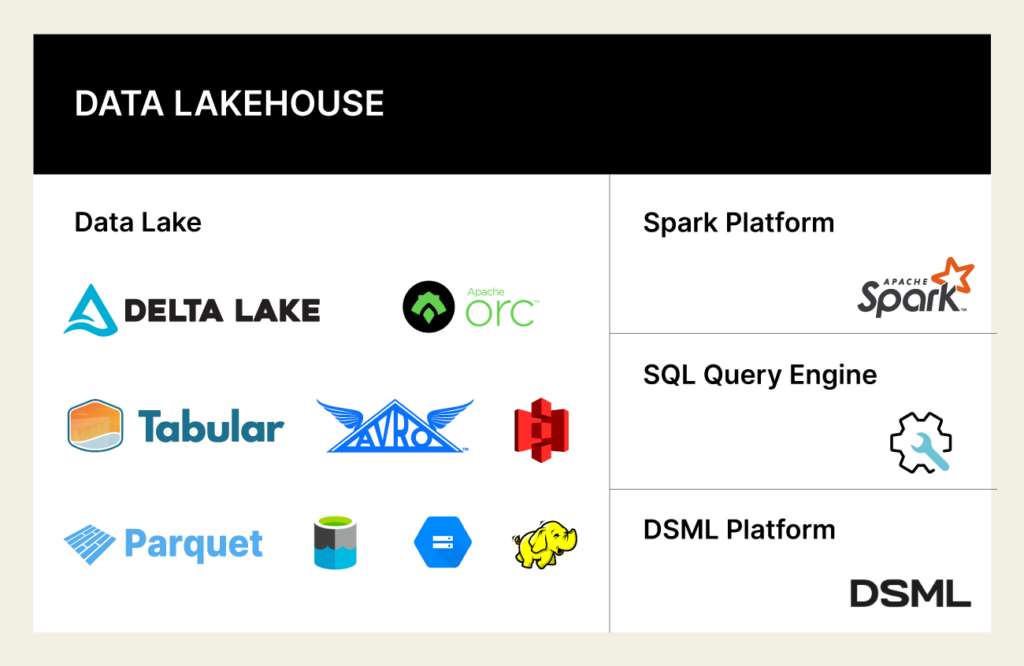
For Andreessen-Horowitz, the fundamental value of the lakehouse is to pair a robust storage layer with an array of powerful data processing engines to deliver a diverse set of data management capabilities to meet both operational and analytical requirements.
Within the data lake side of the lakehouse, object storage is ubiquitous with common implementations from the cloud service providers such as Amazon’s S3, Microsoft’s ADLS, Google’s GCS and the ever-popular Hadoop Disk File System (HDFS).
Columnar storage formats such as Parquet ensure that analytical queries are efficient, both for data compression and performance. Innovation in the storage layer around newer technologies such as Delta, Iceberg and Hudi aims to replicate more of the transactional capabilities of the data warehouse while ensuring interoperability between components in the wider technology stack. Delta Sharing, for example, is the first open protocol for secure data sharing, making it simple to share data with other organizations regardless of which computing platforms they use.
Apache Spark emerged from earlier open-source innovations in the mid-2010s, providing a distributed analytics engine for large-scale data processing. As part of the Spark ecosystem arose capabilities for SQL (‘SparkSQL’) and a wide range of machine learning and artificial intelligence modules that are popular today, such as SparkML and PyTorch.
Innovation is also extremely active around the critical capability of the data lakehouse to run high-performance queries with a SQL front-end – delivering results to reports, dashboards, analyst platforms and machine learning environments. From classic Hadoop-era Hive, to commercial or open-source implementations of Presto or Trino, and more besides, these analytic query accelerators ensure that user queries are optimized for performance against structured data.
Whereas most data lakehouse SQL engines are optimized much like their traditional data warehouse counterparts (i.e. working best on data sets with few joins between data tables), vendors like Incorta offer Direct Data Mapping® technology to ensure that large, complex business application data can be processed and analyzed in the data lakehouse without upfront data transformation or remodeling.
Unlocking legacy data silos with the smart lakehouse
The rise of the data lakehouse is really a tale of two data architectures (the data warehouse and the data lake) meeting in the middle to bring the best of both worlds to a wider audience.
As this journey continues to unfold, innovators will look to bring even more diverse workloads and audiences into the picture. We look to “smart” lakehouse implementations that can work with highly-complex business application data such as Oracle or SAP ERP systems containing thousands of distinct data tables, and aligning this rich content with customer data platforms, third party data or legacy sources.
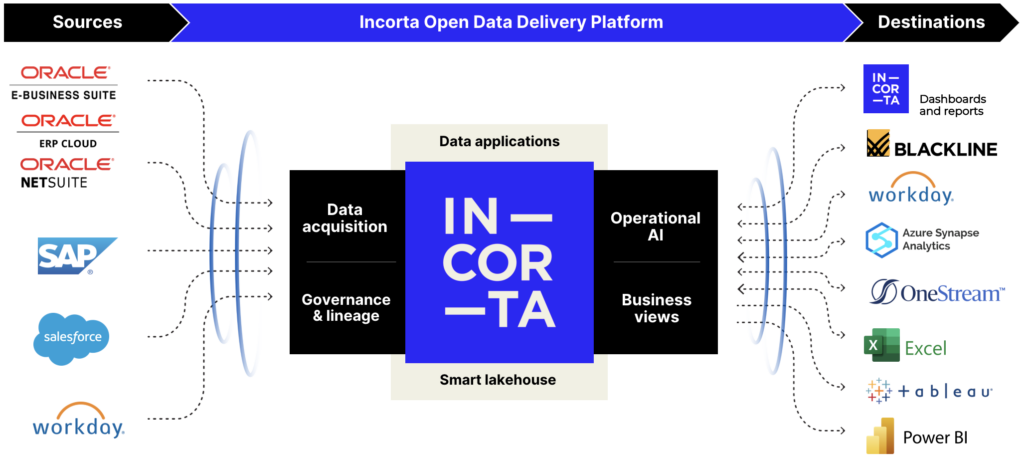
A smart lakehouse understands these source systems without the need for complex or convoluted data processing pipelines. It surfaces real-time business metrics from raw operational data sources that were previously locked away under the tyranny of the nightly ETL batch load. It allows a deep dive from high-level metrics down to the lowest level of detail in the transactions in order to diagnose issues or feed into machine learning models.
Smart lakehouses are also aware of their ecosystem. Gartner’s concerns around data lakehouses are around their nature as a classic ‘monolithic architecture’ (i.e. one that trades feature richness for simplicity).
With strong integrations across the modern data stack, a smart lakehouse can deliver data, analytics and more into cloud-based environments such as Azure Synapse Analytics, Google BigQuery as well as vertical or departmental SaaS solutions such as OneStream or BlackLine. With delta sharing, a smart lakehouse can ensure that data is available for an ever-growing range of data processing and analytic workloads, delivered to the right destination at the right time.
The future looks bright for the data lakehouse architecture as it continues to evolve and offer innovative solutions to complex data challenges!
Learn more about how to unlock 100% of your enterprise data with Incorta’s open data delivery platform, powered by smart lakehouse technology.