

You have undoubtedly heard about ChatGPT and the LLMs that have taken the world by storm. But how did this whirlwind develop? How will it revolutionize data analysis and engineering? More importantly, how can you harness this storm rather than being swept away by it? In this blog post, we’ll embark on a brief journey to answer these questions, accompanied by captivating example showing how to create an advanced data transformation script in a minute. So let’s dive in!
Transformers: the Storm Formation
It all started with Transformers. Transformers are a type of deep learning model that has revolutionized the field of natural language processing (NLP) and other areas of artificial intelligence. They were first introduced in a 2017 paper by Vaswani et al. called “Attention Is All You Need”, and have since become the dominant architecture for NLP tasks.
Before the introduction of transformers, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) were the most popular approaches for NLP. However, these models had limitations in their ability to handle long-term dependencies and capture global context. Moreover, they can not be parallelized. This means we can not train them on massive data in a reasonable time.
The innovation behind transformers is their use of the attention mechanism to encode the context of a sequence of data, such as words in a sentence. This allows transformers to look at all the elements of a sequence simultaneously while also focusing on the most important elements. This approach is more accurate than previous models because it captures the relationships between sequential elements that are far apart. Additionally, transformers are fast at processing sequences because they prioritize the most important parts. This innovation has led to significant improvements in natural language processing tasks and other applications of machine learning.
ChatGPT: The Dawn of Tech Disruption
Originally designed to enhance translations, Transformers soon proved their versatility for general tasks. Companies like OpenAI developed models such as GPT-1, GPT-2, and GPT-3, which were adept at answering questions but lacked conversational capabilities.
In 2022, a groundbreaking technique called “Reinforcement Learning from Human Feedback” was introduced by Ouyang et al. in their paper, “Training language models to follow instructions with human feedback.” OpenAI capitalized on this innovation, launching the GPT-3.5-Turbo model and its accompanying web app, ChatGPT, igniting the disruption.
The technique involves several steps:
- Pairing instructions with correct responses to teach the AI model the basics.
- Refining the model’s behavior using human evaluators to rank different responses.
- Creating a reward system based on feedback to guide the model towards better responses.
- Adjusting the AI model through optimization processes to produce higher-reward responses.
- Repeating the process to gradually improve the model’s performance.
Employing this method, researchers significantly enhanced the AI model’s ability to understand and follow instructions, making it more valuable for tasks involving human interaction. This marked the beginning of the Large Language Models (LLMs) era.
How does it work?
Surprisingly, LLMs aren’t programmed to understand grammar, mathematics, or programming skills. Instead, they are trained on vast amounts of text, learning the probabilities of predicting the next word based on context, paying attention to important words, and fine-tuning their knowledge with curated data.
The idea that a system trained essentially on word prediction probabilities can achieve such feats might leave you puzzled – and you’re not alone. This remarkable outcome continues to baffle one studying it in detail. However, neural networks were inspired by the brain’s intricate and astounding structure of neurons. So, we might be just a few steps away from unlocking the mysteries of the human mind.
Harnessing the Storm
As LLMs engage in human-like discussions, analyze texts, write articles, and generate code, how can data engineers and scientists ride this storm rather than being swept away by it?
It’s essential to recognize that we’re all still discovering how this technology will reshape our work. Broadly speaking, LLMs can be utilized in three ways: by providing a single instruction, engaging in a conversation, or running in auto mode.
Single Instruction
In this use case, you pose a single question to the LLM model and receive one answer. Let’s apply this approach to analyze a set of textual user reviews and extract insights. We have already loaded a table containing three customer reviews into Incorta. Now, we’ll create a Materialized View (MV) that generates the sentiment for each review. Here’s the MV output:
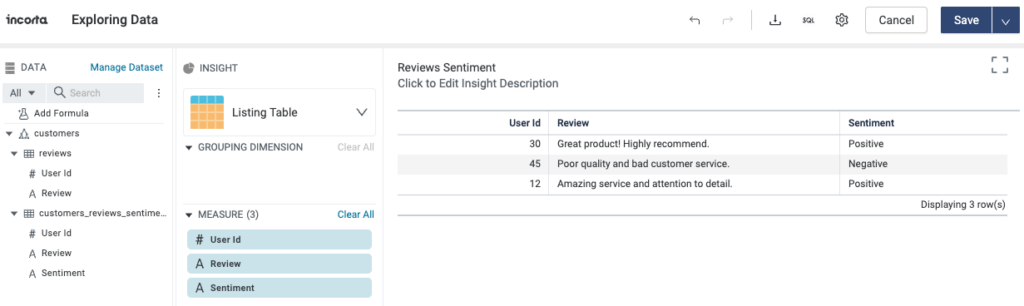
In this example, we’ll incorporate a new programming language alongside the standard Python code within the MV. You will need to learn this new programming language only to create the MV. Here’s the MV code:
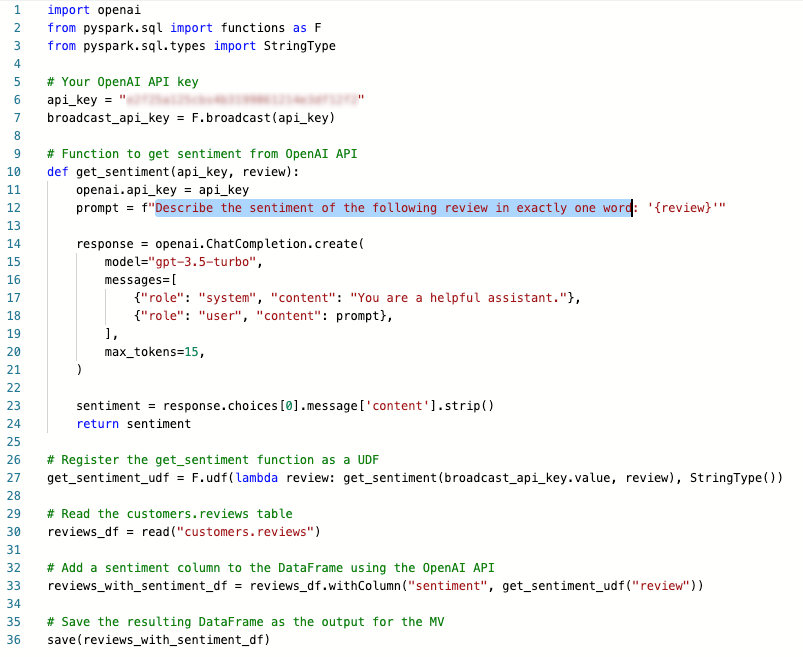
So, what is this unusual new programming language? Found in line 12, it’s called English Programming Language! That’s right – with LLMs, there’s no longer a need to learn traditional programming languages. This is one reason why LLMs are making waves in the tech world. Geeks prefer to call this approach Prompt Engineering. To further illustrate the disruptive potential of LLMs, let’s rewrite the prompt using the Arabic Programming Language and request that it generate the sentiment in Arabic as well:
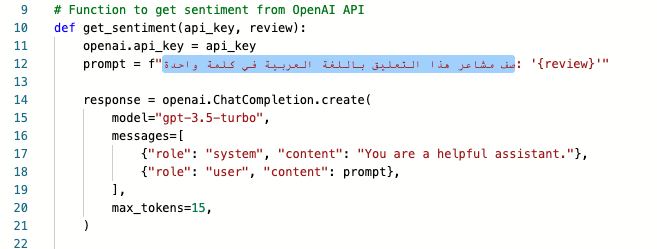
Astonishingly, the results are identical and in Arabic.

You now have access to various natural programming languages at your fingertips. But didn’t we mention that you don’t need any other languages? Indeed, we did. The Python and SQL code above is not ours – it’s the LLM’s creation. Let’s see how this works.
Engaging in a Conversation
In this use case, you engage in an ongoing conversation with the LLM model. We will leverage this to generate the code that we used in the example above automatically. We’ll use GPT-4, the successor of GPT-3.5 or ChatGPT, to generate this code. Here’s the prompt that we employed. The first paragraph is a general one that can be used to pre-train GPT on how to write Materialized Views in Incorta, followed by a single paragraph describing our specific requirements:

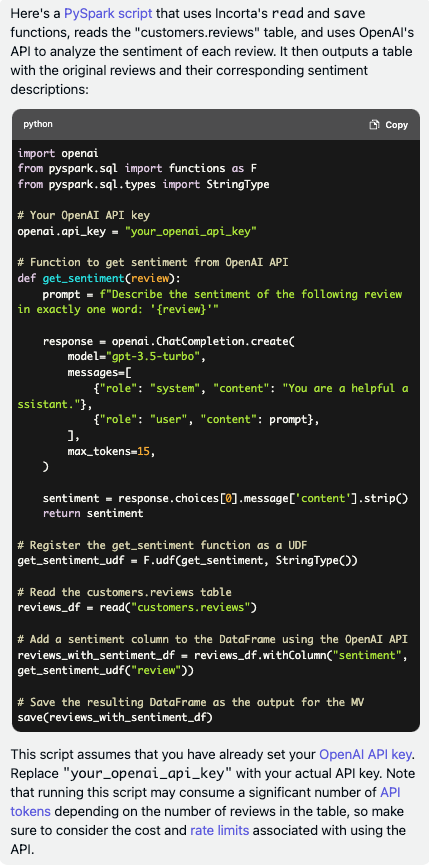
Unfortunately, the code didn’t work and resulted in an error. Let’s ask GPT-4 to diagnose and fix the issue:
We now have the corrected code that we can use immediately. By experimenting with different prompts, you can unlock immense potential for various use cases, especially in unstructured data analysis.
Auto Mode, Auto-GPT or the Hurricane!
We’ve seen how LLMs have taken the world by storm, but the real hurricane arrived on March 30th with the release of Auto-GPT. Auto-GPT is an AI agent that achieves goals in natural language by breaking them into sub-tasks, using the internet and other tools in an automatic loop. It employs OpenAI’s GPT-4 or GPT-3.5 APIs.
The concept behind it involves using Prompt Engineering to instruct ChatGPT to create a set of tasks for a specific goal. For each task, ChatGPT rewrites them in a format that standard programming languages can parse. For instance, when given the task to search the internet for the keyword “football,” ChatGPT generates a JSON like this: {command:"search", "arguments":"football"}. The Auto-GPT engine then understands, parses, and performs the task in reality, returning the output to ChatGPT.
This approach opens the doors to infinite use cases. In our previous example, we could have created an autonomous bot that automatically returns code errors to GPT-4 for continuous fixing until the final code is ready for deployment.
However, Auto-GPT is still a developing technology. It currently struggles with focusing on tasks, decomposing them, or saving them for later use. Additionally, it can be risky and expensive. Time will tell if Auto-GPT will make a landfall or not.
Limitations and Concerns
While exploring the power of LLMs, it’s crucial to consider the following limitations and concerns:
1. Data Security and On-prem Alternatives
To use OpenAI products or other alternatives like Google’s Bard, your data must be sent to their servers. There are open-source alternatives for commercial LLMs, but most are trained on data refined using OpenAI’s GPT model, which violates OpenAI’s terms of service.
Databricks recently released a model called Dolly, based on open-source models and trained from the ground up on genuine data. While not as polished as commercial options, it may serve as a viable on-prem alternative.
2. Cost and Training Limitations
LLM models charge per token, which is roughly a 4-character subset of a word. In conversation mode, you’re charged for the new prompt as well as the entire conversation history with each new prompt. This is because OpenAI and similar models don’t maintain history, requiring the chat UI to send the whole chat history every time to ensure contextually relevant answers.
Additionally, if you need ChatGPT to answer questions based on a document or large context, you must submit the entire document, which can be costly and potentially blocked by maximum token or API call limits.
To address these issues, a trend is emerging to develop lightweight data or LLM processors that can perform preliminary analysis and send up-to-date summaries to LLM models as context. OpenAI has introduced this approach as Plugins, and it is also the core concept behind Auto-GPT.
Disclaimer
This blog post was written by human authors in flesh! Alright, we did use ChatGPT for some parts of the blog, but when we asked ChatGPT, “I will write a blog post and will use you for parts of it. Should I include ChatGPT in the authors list? Please answer with either YES or NO only,” it responded with “NO”! So, we’re all good!
Co-Authored by: Hania Anwar